Making a Custom algorithm
ここでは本フレームワークの自作アルゴリズムを作成する方法を説明します。
1.概要
- 2.実装するクラス
2-1.Config
2-2.Memory
2-3.Parameter
2-4.Trainer
2-5.Worker
3.自作アルゴリズムの登録
4.型ヒント
5.Q学習実装例
1. 概要
# 学習単位の初期化
parameter.setup()
memory.setup()
worker.on_setup()
trainer.on_setup()
for episode in range(N)
# 1エピソード最初の初期化
env.reset()
worker.on_reset()
# 1エピソードのループ
while not env.done:
# アクションを取得
action = worker.policy()
worker.render() # workerの描画
# 環境の1stepを実行
env.step(action)
worker.on_step()
# 学習
trainer.train()
# 終了後の描画
worker.render()
# 学習単位の終了
worker.on_teardown()
trainer.on_teardown()
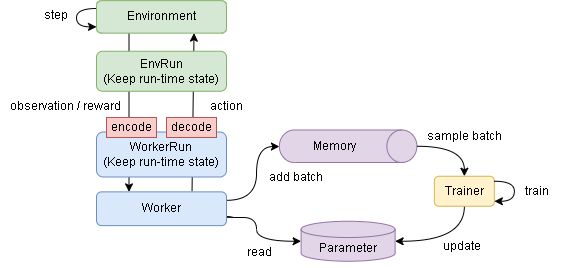
Config |
|
Memory |
|
Parameter |
|
Trainer |
|
Worker |
|
分散学習は以下となり各クラスが非同期で動作します。
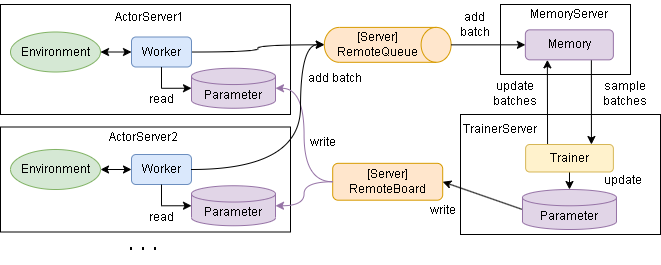
・MemoryとTrainerが非同期
・MemoryとTrainerが同期
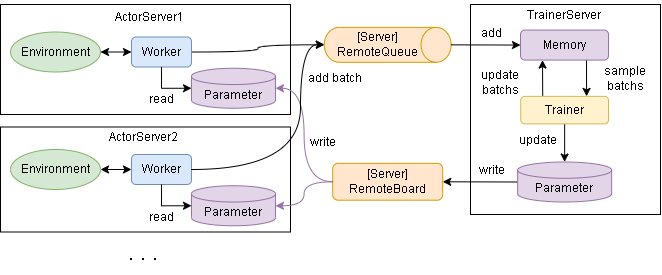
同期的な学習と以下の点が異なります。
WorkerがMemoryにサンプルを送るタイミングとTrainerが取り出すタイミングが異なる
ParameterがWorkerとTrainerで別インスタンス
各クラスの実装の仕方を見ていきます。
2. 実装する各クラスの説明
2-1. Config
from dataclasses import dataclass
from srl.base.rl.config import RLConfig
from srl.base.define import RLBaseTypes
from srl.base.rl.processor import Processor
# 必ず dataclass で書いてください
@dataclass
class MyConfig(RLConfig):
# 任意のハイパーパラメータを定義
hoo_param: float = 0
bar_param: float = 0
def get_name(self) -> str:
""" ユニークな名前を返す """
raise NotImplementedError()
def get_base_action_type(self) -> RLBaseTypes:
"""
アルゴリズムが想定するアクションのタイプを指定してください。
"""
raise NotImplementedError()
def get_base_observation_type(self) -> RLBaseTypes:
"""
アルゴリズムが想定する環境から受け取る状態のタイプを指定してください。
"""
raise NotImplementedError()
# ------------------------------------
# 以下は option です。(なくても問題ありません)
# ------------------------------------
def get_framework(self) -> str:
"""
使うフレームワークを指定してください。
return "" : なし(default)
return "tensorflow" : Tensorflow
return "torch" : Torch
"""
raise NotImplementedError()
def validate_params(self) -> None:
""" パラメータのassertを記載 """
super().validate_params() # 定義する場合は親クラスも呼び出してください
def setup_from_env(self, env: EnvRun) -> None:
""" env初期化後に呼び出されます。env関係の初期化がある場合は記載してください。 """
pass
def setup_from_actor(self, actor_num: int, actor_id: int) -> None:
""" 分散学習でactorが指定されたときに呼び出されます。Actor関係の初期化がある場合は記載してください。 """
pass
def get_processors(self, prev_observation_space: SpaceBase) -> List[RLProcessor]:
""" 前処理を追加したい場合設定してください """
return []
def use_backup_restore(self) -> bool:
""" MCTSなど、envのbackup/restoreを使う場合はTrueを返してください"""
return False
# use_render_image_stateをTrueにするとworker.render_img_stateが有効になります
# これはenv.render_rgb_arrayの画像が入ります
def use_render_image_state(self) -> bool:
return False
def get_render_image_processors(self, prev_observation_space: SpaceBase) -> List[RLProcessor]:
"""render_img_stateに対する前処理"""
return []
2-2. Memory
SingleUseBuffer |
来たサンプルを順序通りに取り出します。(Queueみたいな動作です) |
ReplayBuffer |
サンプルをランダムに取り出します。 |
PriorityReplayBuffer |
サンプルを優先順位に従い取り出します。 |
RLSingleUseBuffer
順番通りにサンプルを取り出しますMemoryです。サンプルは取り出すとなくなります。
from srl.base.rl.config import DummyRLConfig
from srl.rl.memories.single_use_buffer import RLSingleUseBuffer
class MyRemoteMemory(RLSingleUseBuffer):
pass
memory = MyRemoteMemory(DummyRLConfig())
memory.add([1, 2])
memory.add([2, 3])
memory.add([3, 4])
dat = memory.sample()
print(dat) # [[1, 2], [2, 3], [3, 4]]
RLReplayBuffer
from dataclasses import dataclass, field
from srl.base.rl.config import DummyRLConfig
from srl.rl.memories.replay_buffer import ReplayBufferConfig, RLReplayBuffer
@dataclass
class MyConfig(DummyRLConfig):
batch_size: int = 2 # batch_sizeを実装する必要あり
memory: ReplayBufferConfig = field(
default_factory=lambda: ReplayBufferConfig(
warmup_size=2,
)
)
class MyRemoteMemory(RLReplayBuffer):
pass
memory = MyRemoteMemory(MyConfig())
memory.add(1)
memory.add(2)
memory.add(3)
memory.add(4)
dat = memory.sample()
print(dat) # [3, 2]
RLPriorityReplayBuffer
クラス名 |
説明 |
|---|---|
set_replay_buffer |
ReplayBufferと同じで、ランダムに取得します。(優先順位はありません) |
set_proportional |
サンプルの重要度によって確率が変わります。重要度が高いサンプルほど選ばれる確率が上がります。 |
set_rankbased |
サンプルの重要度のランキングによって確率が変わります。重要度が高いサンプルほど選ばれる確率が上がるのはProportionalと同じです。 |
set_rankbased_linear |
rankbasedと同じですが、指数的な計算で複雑なrankbasedをlinearを仮定することで高速化したアルゴリズムです。 |
from dataclasses import dataclass, field
import numpy as np
from srl.base.rl.config import DummyRLConfig
from srl.rl.memories.priority_replay_buffer import PriorityReplayBufferConfig, RLPriorityReplayBuffer
@dataclass
class MyConfig(DummyRLConfig):
batch_size: int = 2 # batch_sizeを実装する必要あり
memory: PriorityReplayBufferConfig = field(
default_factory=lambda: PriorityReplayBufferConfig(
warmup_size=2,
)
)
class MyRemoteMemory(RLPriorityReplayBuffer):
pass
config = MyConfig()
# --- select memory
# config.memory.set_replay_buffer()
config.memory.set_proportional()
# config.memory.set_proportional_cpp()
# config.memory.set_rankbased()
# config.memory.set_rankbased_linear()
# --- run memory
memory = MyRemoteMemory(config)
memory.add(1, priority=1)
memory.add(2, priority=2)
memory.add(3, priority=3)
memory.add(4, priority=4)
batches, weights, update_args = memory.sample()
print(batches) # [3, 1]
memory.update(update_args, np.array([1, 2]), step=1)
オリジナルMemoryの作成
register_worker_func |
Worker -> Memory の関数を登録します。 |
register_trainer_recv_func |
Memory -> Trainer の関数を登録します。 |
register_trainer_send_func |
Trainer -> Memory の関数を登録します。 |
from srl.base.rl.memory import RLMemory
import numpy as np
class MyMemory(RLMemory):
def setup(self) -> None:
# self.config に上で定義した MyConfig が入っています
# Worker -> Memory用の関数を登録
self.register_worker_func(self.add)
# Memory -> Trainer用の関数を登録
self.register_trainer_recv_func(self.sample)
# Trainer -> Memory用の関数を登録
self.register_trainer_send_func(self.update)
def add(self, batch) -> None:
# Worker->Memoryの送信で使う関数の書式例
# - 引数は任意
# - 戻り値はNone固定
raise NotImplementedError()
def sample(self) -> Any:
# Memory->Trainerの送信で使う関数の書式例
# - 引数はなし
# - 戻り値は任意の型
raise NotImplementedError()
def update(self, batch) -> None:
# Trainer->Memoryの送信で使う関数の書式例
# - 引数は任意
# - 戻り値はNone固定
raise NotImplementedError()
# オプションですが、定義するとSRL内の必要な場所で呼び出されます。(主に表示)
def length(self) -> int:
return -1
# call_restore/call_backupでパラメータが復元できるように作成
def call_restore(self, data, **kwargs) -> None:
raise NotImplementedError()
def call_backup(self, **kwargs):
raise NotImplementedError()
# その他任意の関数を作成できます。
※ v0.19.0 より __init__ の使用は非推奨となりました。代わりにsetupを使ってください。
2-3. Parameter
from srl.base.rl.parameter import RLParameter
import numpy as np
class MyParameter(RLParameter):
def setup(self):
# self.config に上で定義した MyConfig が入っています
pass
# call_restore/call_backupでパラメータが復元できるように作成
def call_restore(self, data, **kwargs) -> None:
raise NotImplementedError()
def call_backup(self, **kwargs):
raise NotImplementedError()
# その他任意の関数を作成できます。
# 分散学習ではTrainer/Worker間で値を保持できない点に注意(backup/restoreした値のみ共有されます)
※ v0.19.0 より __init__ の使用は非推奨となりました。代わりにsetupを使ってください。
2-4. Trainer
from srl.base.rl.trainer import RLTrainer
class MyTrainer(RLTrainer):
def on_setup(self) -> None:
# 以下の変数を持ちます。
# self.config: MyConfig
# self.parameter: MyParameter
# self.memory: MyMemory
#
# 他にも以下のプロパティが使えます
# self.distributed - property, bool : 分散実行中かどうかを返します
# self.train_only - property, bool : 学習のみかどうかを返します
#
pass
def train(self) -> None:
"""
self.memory から batch を受け取り学習する事を想定しています。
・学習したら回数を数えてください
self.train_count += 1
・(option)必要に応じてinfoを設定します
self.info = {"loss": 0.0}
"""
raise NotImplementedError()
※ v0.19.0 より __init__ の使用は非推奨となりました。代わりにon_setupを使ってください。
2-5. Worker
フローをすごく簡単に書くと以下です。
env.reset()
worker.on_reset()
while:
action = worker.policy()
env.step(action)
worker.on_step()
trainer.train()
from srl.base.rl.worker import RLWorker
from srl.base.rl.worker_run import WorkerRun
class MyWorker(RLWorker):
def on_setup(self, worker: WorkerRun, context: RunContext) -> None:
# 以下の変数を持ちます。
# self.config: MyConfig
# self.parameter: MyParameter
# self.memory: MyMemory
pass
def on_teardown(self, worker) -> None:
pass
def on_reset(self, worker: WorkerRun):
""" エピソードの最初に呼ばれる関数 """
raise NotImplementedError()
def policy(self, worker: WorkerRun) -> RLActionType:
""" このターンで実行するアクションを返す関数、この関数のみ実装が必須になります
Returns:
RLActionType : 実行するアクション
"""
raise NotImplementedError()
def on_step(self, worker: WorkerRun):
""" Envが1step実行した後に呼ばれる関数 """
raise NotImplementedError()
def render_terminal(self, worker, **kwargs) -> None:
"""
描画用の関数です。
実装するとrenderによる描画が可能になります。
"""
pass
def render_rgb_array(self, worker, **kwargs) -> Optional[np.ndarray]:
"""
描画用の関数です。
実装するとrenderによる描画が可能になります。
"""
return None
# --- 実装時に関数内で使う事を想定しているプロパティ・関数となります
self.training # property, bool : training かどうかを返します
self.distributed # property, bool : 分散実行中かどうかを返します
self.rendering # property, bool : renderがあるエピソードかどうかを返します
self.observation_space # property , SpaceBase : RLWorkerが受け取るobservation_spaceを返します
self.action_space # property , SpaceBase : RLWorkerが受け取るaction_spaceを返します
self.get_invalid_actions() # function , List[RLAction] : 有効でないアクションを返します(離散限定)
self.sample_action() # function , RLAction : ランダムなアクションを返します
class MyWorker(RLWorker):
def on_reset(self, worker):
worker.state # 初期状態
worker.player_index # 初期プレイヤーのindex
worker.invalid_actions # 初期有効ではないアクションリスト
def policy(self, worker) :
worker.state # 状態
worker.player_index # プレイヤーのindex
worker.invalid_actions # 有効ではないアクションリスト
def on_step(self, worker: "WorkerRun") -> dict:
worker.state # policy時のworker.state
worker.next_state # step後の状態
worker.action # policyで返したアクション
worker.reward # step後の即時報酬
worker.done # step後に終了フラグが立ったか
worker.terminated # step後にenvが終了フラグを立てたか
worker.player_index # 次のプレイヤーのindex
worker.invalid_action # policy時のworker.invalid_action
worker.next_invalid_actions # step後の有効ではないアクションリスト
def render_terminal(self, worker): # 及び render_rgb_array
# policy -> render -> env.step -> on_step -> policy
# 想定する役割は、policy直後の状態の表示 + 前の状態の結果を表示
worker.state # policy時の状態
worker.prev_state # policy時の1つ前の状態
worker.action # policyで返したアクション
worker.player_index # プレイヤーのindex
worker.invalid_actions # policy時の有効ではないアクションリスト
worker.prev_invalid_actions # policy時の1つ前の有効ではないアクションリスト
3. 自作アルゴリズムの登録
from srl.base.rl.registration import register
register(
MyConfig(),
__name__ + ":MyMemory",
__name__ + ":MyParameter",
__name__ + ":MyTrainer",
__name__ + ":MyWorker",
)
4. 型ヒント
# from srl.rl.config import RLConfig
# from srl.rl.worker import RLWorker
# ↓
from srl.base.rl.algorithms.base_dqn import RLConfig, RLWorker
# srl.base.rl.algorithms.base_XX の XX の部分を変更する事でアルゴリズムに合った型に変更できます
# XX の種類についてはソースコードを見てください。
また、ジェネリック型を追加する事で各クラスの型を追加できます。
# RLMemory[TConfig]
# TConfig : RLConfigを継承したクラス
class Memoryr(RLMemory[Config]):
pass
# RLParameter[TConfig]
# TConfig : RLConfigを継承したクラス
class Parameter(RLParameter[Config]):
pass
# RLTrainer[TConfig, TParameter, TMemory]
# TConfig : RLConfigを継承したクラス
# TParameter : RLParameterを継承したクラス
# TMemory : RLMemoryを継承したクラス
class Trainer(RLTrainer[Config, Parameter, Memory]):
pass
# RLWorker[TConfig, TParameter]
# TConfig : RLConfigを継承したクラス
# TParameter : RLParameterを継承したクラス
# TMemory : RLMemoryを継承したクラス
class Worker(RLWorker[Config, Parameter, Memory]):
pass
5. 実装例(Q学習)
import json
import random
from dataclasses import dataclass
import numpy as np
from srl.base.define import RLBaseTypes
from srl.base.rl.config import RLConfig
from srl.base.rl.memory import RLMemory
from srl.base.rl.parameter import RLParameter
from srl.base.rl.registration import register
from srl.base.rl.trainer import RLTrainer
from srl.base.rl.worker import RLWorker
from srl.base.spaces.array_discrete import ArrayDiscreteSpace
from srl.base.spaces.discrete import DiscreteSpace
@dataclass
class Config(RLConfig[DiscreteSpace, ArrayDiscreteSpace]):
epsilon: float = 0.1
test_epsilon: float = 0
gamma: float = 0.9
lr: float = 0.1
def get_base_action_type(self) -> RLBaseTypes:
return RLBaseTypes.DISCRETE
def get_base_observation_type(self) -> RLBaseTypes:
return RLBaseTypes.DISCRETE
def get_name(self) -> str:
return "MyRL"
# 継承する場合
# from srl.rl.memories.single_use_buffer import RLSingleUseBuffer
# class Memory(RLSingleUseBuffer):
# pass
class Memory(RLMemory[Config]):
def setup(self):
self.buffer = []
self.register_worker_func(self.add)
self.register_trainer_recv_func(self.sample)
def length(self) -> int:
return len(self.buffer)
def add(self, batch) -> None:
self.buffer.append(batch)
def sample(self):
if len(self.buffer) == 0:
return None
buffer = self.buffer
self.buffer = []
return buffer
def call_backup(self, **kwargs):
return self.buffer[:]
def call_restore(self, data, **kwargs) -> None:
self.buffer = data[:]
class Parameter(RLParameter[Config]):
def setup(self):
self.Q = {} # Q学習用のテーブル
def call_restore(self, data, **kwargs) -> None:
self.Q = json.loads(data)
def call_backup(self, **kwargs):
return json.dumps(self.Q)
# Q値を取得する関数
def get_action_values(self, state: str):
if state not in self.Q:
self.Q[state] = [0] * self.config.action_space.n
return self.Q[state]
class Trainer(RLTrainer[Config, Parameter, Memory]):
def on_setup(self) -> None:
pass
def train(self) -> None:
batches = self.memory.sample()
if batches is None:
return
td_error = 0
for batch in batches:
# 各batch毎にQテーブルを更新する
s = batch["state"]
n_s = batch["next_state"]
action = batch["action"]
reward = batch["reward"]
done = batch["done"]
q = self.parameter.get_action_values(s)
n_q = self.parameter.get_action_values(n_s)
if done:
target_q = reward
else:
target_q = reward + self.config.gamma * max(n_q)
td_error = target_q - q[action]
q[action] += self.config.lr * td_error
td_error += td_error
self.train_count += 1 # 学習回数
if len(batches) > 0:
td_error /= len(batches)
# 学習結果(任意)
self.info["Q"] = len(self.parameter.Q)
self.info["td_error"] = td_error
class Worker(RLWorker[Config, Parameter, Memory]):
def on_setup(self, worker, context) -> None:
pass
def on_teardown(self, worker) -> None:
pass
def on_reset(self, worker):
pass
def policy(self, worker) -> int:
self.state = self.config.observation_space.to_str(worker.state)
# 学習中かどうかで探索率を変える
if self.training:
epsilon = self.config.epsilon
else:
epsilon = self.config.test_epsilon
if random.random() < epsilon:
# epsilonより低いならランダムに移動
action = self.sample_action()
else:
q = self.parameter.get_action_values(self.state)
q = np.asarray(q)
# 最大値を選ぶ(複数あればランダム)
action = np.random.choice(np.where(q == q.max())[0])
return int(action)
def on_step(self, worker):
if not self.training:
return
self.memory.add(
{
"state": self.state,
"next_state": self.config.observation_space.to_str(worker.next_state),
"action": worker.action,
"reward": worker.reward,
"done": worker.terminated,
}
)
# 強化学習の可視化用、今回ですとQテーブルを表示しています。
def render_terminal(self, worker, **kwargs):
q = self.parameter.get_action_values(self.state)
maxa = np.argmax(q)
for a in range(self.config.action_space.n):
if a == maxa:
s = "*"
else:
s = " "
s += f"{worker.env.action_to_str(a)}: {q[a]:7.5f}"
print(s)
# ---------------------------------
# 登録
# ---------------------------------
register(
Config(),
__name__ + ":Memory",
__name__ + ":Parameter",
__name__ + ":Trainer",
__name__ + ":Worker",
)
def test():
from srl.test.rl import test_rl
test_rl(Config())
def main():
# --- Grid環境の学習
import srl
runner = srl.Runner(srl.EnvConfig("Grid"), Config(lr=0.001))
# --- train
runner.train(timeout=10)
runner.train_mp(timeout=10)
# --- test
rewards = runner.evaluate(max_episodes=100)
print("100エピソードの平均結果", np.mean(rewards))
runner.render_terminal()
runner.animation_save_gif("_MyRL-Grid.gif", render_scale=2)
if __name__ == "__main__":
# test()
main()
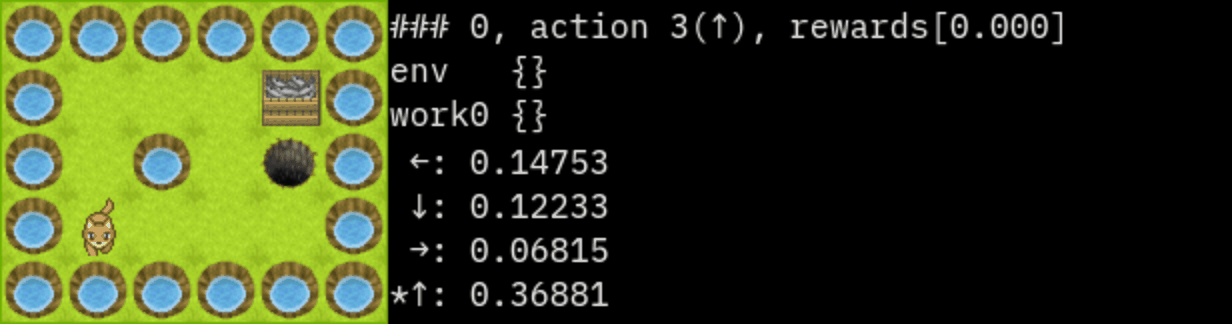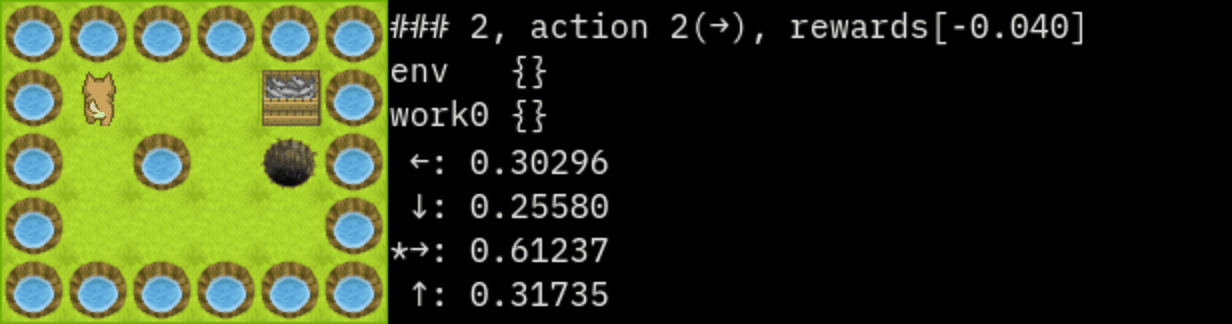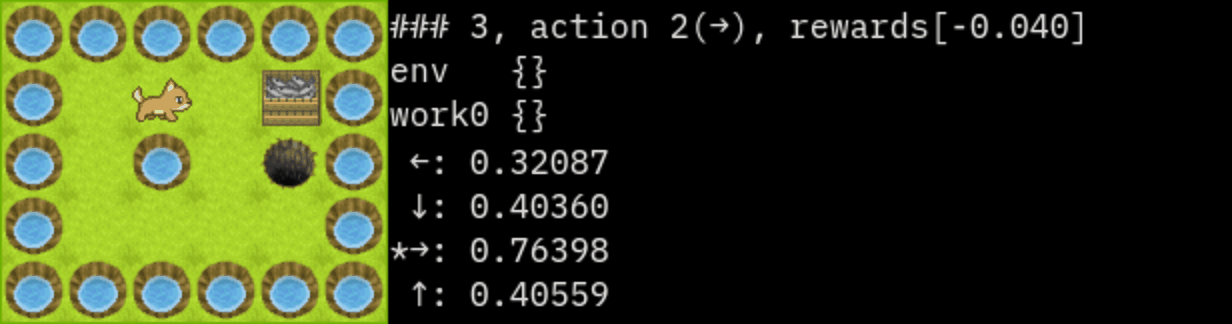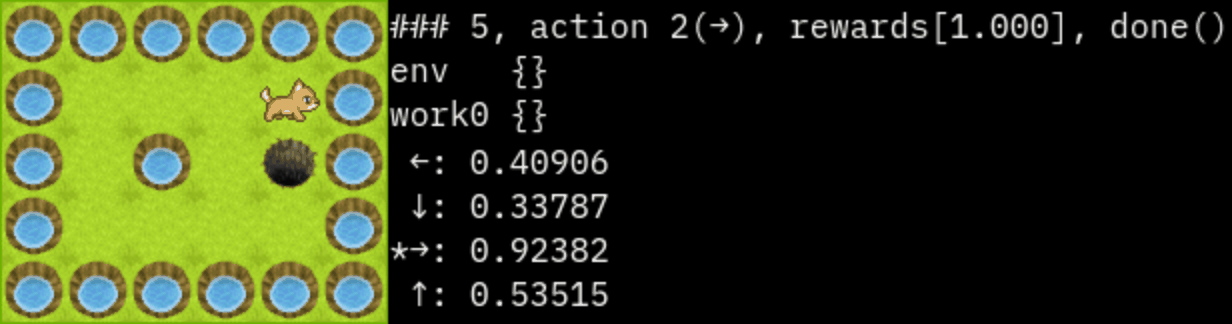
renderの表示例
100エピソードの平均結果 0.7347999999999999
......
. G.
. . X.
.P .
......
←: 0.15227
↓: 0.13825
→: 0.08833
*↑: 0.36559
### 0
state: 1,3
action : 3(↑)
rewards:[0.000]
env {}
work0 {}
......
. G.
.P. X.
.S .
......
←: 0.24042
↓: 0.17950
→: 0.23959
*↑: 0.48550
### 1
state: 1,2
action : 3(↑)
rewards:[-0.040]
env {}
work0 {}
......
.P G.
. . X.
.S .
......
←: 0.30830
↓: 0.25582
*→: 0.60909
↑: 0.31496
### 2
state: 1,1
action : 2(→)
rewards:[-0.040]
env {}
work0 {}
......
.P G.
. . X.
.S .
......
←: 0.30830
↓: 0.25582
*→: 0.60909
↑: 0.31496
### 3
state: 1,1
action : 2(→)
rewards:[-0.040]
env {}
work0 {}
......
. G.
.P. X.
.S .
......
←: 0.24042
↓: 0.17950
→: 0.23959
*↑: 0.48550
### 4
state: 1,2
action : 3(↑)
rewards:[-0.040]
env {}
work0 {}
......
. G.
.P. X.
.S .
......
←: 0.24042
↓: 0.17950
→: 0.23959
*↑: 0.48550
### 5
state: 1,2
action : 3(↑)
rewards:[-0.040]
env {}
work0 {}
......
.P G.
. . X.
.S .
......
←: 0.30830
↓: 0.25582
*→: 0.60909
↑: 0.31496
### 6
state: 1,1
action : 2(→)
rewards:[-0.040]
env {}
work0 {}
......
.P G.
. . X.
.S .
......
←: 0.30830
↓: 0.25582
*→: 0.60909
↑: 0.31496
### 7
state: 1,1
action : 2(→)
rewards:[-0.040]
env {}
work0 {}
......
. P G.
. . X.
.S .
......
←: 0.33411
↓: 0.40200
*→: 0.76411
↑: 0.41102
### 8
state: 2,1
action : 2(→)
rewards:[-0.040]
env {}
work0 {}
......
. PG.
. . X.
.S .
......
←: 0.42417
↓: 0.36094
*→: 0.92805
↑: 0.54881
### 9
state: 3,1
action : 2(→)
rewards:[-0.040]
env {}
work0 {}
......
. P.
. . X.
.S .
......
←: 0.42417
↓: 0.36094
*→: 0.92805
↑: 0.54881
### 10, done()
state: 4,1
action : 2(→)
rewards:[1.000]
env {}
work0 {}