How To Use
以下の3手順となります。
環境を設定(EnvConfig)
アルゴリズムを設定(RLConfig)
Runnerで動かす
1. EnvConfig
実行する環境を指定します。
import srl
env_config = srl.EnvConfig("Grid")
Gym/Gymnasium の環境とも互換があり指定できます。
import srl
env_config = srl.EnvConfig("FrozenLake-v1")
自作の環境を用意したい場合は Making a Custom environment を見てください。
また、ID以外にEnvConfigに設定できる項目は EnvConfig を見てください。
Gym/Gymnasiumに対応していない環境の読み込み
'gym_make_func' 'gymnasium_make_func' に読み込む関数を指定することができます。
例は 'gym-retro' を読み込む例です。
# pip install gym-retro
# gym-retro==0.8.0 support python3.6 3.7 3.8 and gym<=0.25.2
import retro
import srl
from srl.utils import common
common.logger_print()
env_config = srl.EnvConfig(
"Airstriker-Genesis",
dict(state="Level1"),
gym_make_func=retro.make,
)
runner = srl.Runner(env_config)
runner.render_window()
2. RLConfig
実行するアルゴリズムを指定します。
各アルゴリズムにはConfigがあるのでそれを呼び出します。
# 使うアルゴリズムを読み込み
from srl.algorithms import ql
rl_config = ql.Config()
各アルゴリズムのハイパーパラメータはConfigの変数で値を指定できます。
# 割引率を変更する例
rl_config = ql.Config(discount=0.5)
# インスタンス後に書き換えも可能
rl_config.discount = 0.3
各アルゴリズムのハイパーパラメータについては srl.algorithms 配下のそれぞれのコードを見てください。
また、共通パラメータに関しては RLConfig を参照してください。
3. Runner
EnvConfigとRLConfigを元に実際に実行するRunnerを作成します。
import srl
# Runnerの引数にEnvConfigとRLConfigを指定
env_config = srl.EnvConfig("Grid")
rl_config = ql.Config()
runner = srl.Runner(env_config, rl_config)
# envはIDのみでも指定可能
runner = srl.Runner("Grid", rl_config)
# envのみの指定も可能(ただしアルゴリズムを使うものは利用できない)
runner = srl.Runner("Grid")
Runnerを作成したら後は任意の関数を実行して学習します。
Basic run of study
import srl
from srl.algorithms import ql # algorithm load
def main():
# create Runner
runner = srl.Runner("Grid", ql.Config())
# train
runner.train(timeout=10)
# evaluate
rewards = runner.evaluate()
print(f"evaluate episodes: {rewards}")
if __name__ == "__main__":
main()
Commonly run Example
import numpy as np
import srl
from srl.algorithms import ql # algorithm load
from srl.utils import common
common.logger_print()
# --- save parameter path
_parameter_path = "_params.dat"
# --- sample config
# For the parameters of Config, refer to the argument completion or the original code.
def _create_runner(load_parameter: bool):
env_config = srl.EnvConfig("Grid")
rl_config = ql.Config()
runner = srl.Runner(env_config, rl_config)
# --- load parameter
if load_parameter:
runner.load_parameter(_parameter_path)
return runner
# --- train sample
def train(timeout=10):
runner = _create_runner(load_parameter=False)
# sequence training
runner.train(timeout=timeout)
# save parameter
runner.save_parameter(_parameter_path)
# --- evaluate sample
def evaluate():
runner = _create_runner(load_parameter=True)
rewards = runner.evaluate(max_episodes=100)
print(rewards)
print(f"Average reward for 100 episodes: {np.mean(rewards, axis=0)}")
# --- render terminal sample
def render_terminal():
runner = _create_runner(load_parameter=True)
runner.render_terminal()
# --- render window sample
# (Run "pip install pillow pygame" to use the render_window)
def render_window():
runner = _create_runner(load_parameter=True)
runner.render_window()
# --- animation sample
# (Run "pip install opencv-python pillow pygame" to use the animation)
def animation():
runner = _create_runner(load_parameter=True)
runner.animation_save_gif("_Grid.gif")
# --- replay window sample
# (Run "pip install opencv-python pillow pygame" to use the replay_window)
def replay_window():
runner = _create_runner(load_parameter=True)
runner.replay_window()
if __name__ == "__main__":
train()
evaluate()
# render_terminal()
# render_window()
# animation()
replay_window()
4. Runner functions
Runnerで実行できる各関数に関してです。
Train
学習をします。
学習後のParameterとMemoryがRunner内に保存されます。
runner.train(max_episode=10)
Rollout
経験を集める時に使います。
実際に学習環境でエピソードを実行しますが、学習はしません。
実行後はMemoryがRunner内に保存されます。
runner.rollout(max_episode=10)
Train Only
エピソードは実行せず、Trainerの学習のみを実施します。
Memoryにbatchがない状態など、学習出来ない場合で実行すると無限ループになるので注意してください。
runner.train_only(max_train_count=10)
Train Multiprocessing
multiprocessing による分散学習を実施します。
runner.train_mp(max_train_count=10)
MLflow Train
学習内容をMLFlowで記録します。
import mlflow
import srl
from srl.algorithms import ql, vanilla_policy
from srl.utils import common
#
# MLFlow docs: https://mlflow.org/docs/latest/ml/
#
# Launch the MLflow Web UI (see the "mlruns" directory)
# > mlflow ui --backend-store-uri mlruns
#
# Save the data in the "mlruns" directory
mlflow.set_tracking_uri("mlruns")
def create_ql_runner():
env_config = srl.EnvConfig("Grid")
rl_config = ql.Config()
return srl.Runner(env_config, rl_config)
def train_ql(timeout=30):
runner = create_ql_runner()
# Configuring Data Collection for MLFlow
runner.set_mlflow(checkpoint_interval=10)
runner.train(timeout=timeout)
# Create an HTML video for all the parameters stored in MLFlow.
runner.make_html_all_parameters_in_mlflow()
def load_ql_parameter():
runner = create_ql_runner()
# Load parameters saved in MLFlow
runner.load_parameter_from_mlflow()
rewards = runner.evaluate()
print(rewards)
def train_vanilla_policy(timeout=30):
env_config = srl.EnvConfig("Grid")
rl_config = vanilla_policy.Config()
runner = srl.Runner(env_config, rl_config)
# Run directly using MLFlow
runner.set_mlflow()
mlflow.set_experiment("MyExperimentName")
with mlflow.start_run(run_name="MyRunName"):
runner.train(timeout=timeout)
if __name__ == "__main__":
common.logger_print()
train_ql()
load_ql_parameter()
train_vanilla_policy()
Evaluate
学習せずにシミュレーションし、報酬を返します。
import srl
from srl.algorithms import ql
runner = srl.Runner("Grid", ql.Config())
runner.train(timeout=1)
rewards = runner.evaluate(max_episodes=5)
print(f"evaluate episodes: {rewards}")
"""
evaluate episodes: [0.76, 0.8, 0.72, 0.76, 0.84]
"""
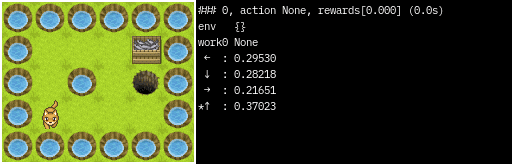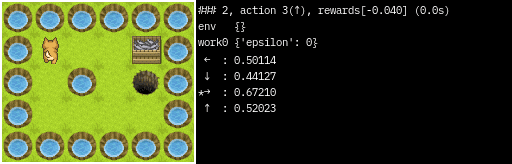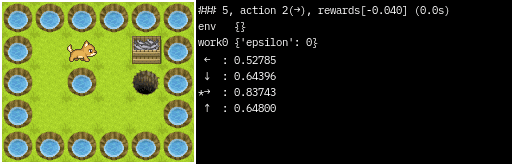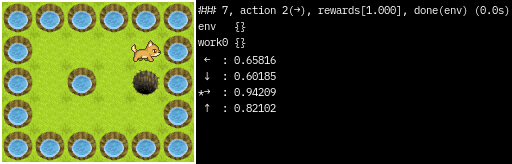
Render Terminal
print出力の形式で1エピソードシミュレーションします。
import srl
from srl.algorithms import ql
runner = srl.Runner("Grid", ql.Config())
runner.train(timeout=5)
runner.render_terminal()
"""
### 0
state : 1,3
action : None
rewards:[0.000]
total rewards:[0.000]
env {}
work0 {'epsilon': 0.1}
......
. G.
. . X.
.P .
......
0(←) : 0.31790
1(↓) : 0.30021
2(→) : 0.22420
*3(↑) : 0.40947
### 1
state : 1,2
action : 3(↑)
rewards:[-0.040]
total rewards:[-0.040]
env {}
work0 {'epsilon': 0}
......
. G.
.P. X.
.S .
......
0(←) : 0.41061
1(↓) : 0.30757
2(→) : 0.37957
*3(↑) : 0.51605
### 2
state : 1,2
action : 3(↑)
rewards:[-0.040]
total rewards:[-0.080]
env {}
work0 {'epsilon': 0}
......
. G.
.P. X.
.S .
......
0(←) : 0.41061
1(↓) : 0.30757
2(→) : 0.37957
*3(↑) : 0.51605
### 3
state : 1,1
action : 3(↑)
rewards:[-0.040]
total rewards:[-0.120]
env {}
work0 {'epsilon': 0}
......
.P G.
. . X.
.S .
......
0(←) : 0.50963
1(↓) : 0.47168
*2(→) : 0.63577
3(↑) : 0.52524
### 4
state : 2,1
action : 2(→)
rewards:[-0.040]
total rewards:[-0.160]
env {}
work0 {'epsilon': 0}
......
. P G.
. . X.
.S .
......
0(←) : 0.55444
1(↓) : 0.65966
*2(→) : 0.76021
3(↑) : 0.64972
### 5
state : 3,1
action : 2(→)
rewards:[-0.040]
total rewards:[-0.200]
env {}
work0 {'epsilon': 0}
......
. PG.
. . X.
.S .
......
0(←) : 0.65326
1(↓) : 0.51852
*2(→) : 0.95872
3(↑) : 0.78929
......
. P.
. . X.
.S .
......
### 6, done()
state : 4,1
action : 2(→)
rewards:[1.000]
total rewards:[0.800]
env {}
work0 {'epsilon': 0}
"""
Render Window
1エピソードを描画します。 pygameのwindowが表示できる環境である必要があります。
import srl
from srl.algorithms import ql
runner = srl.Runner("Grid", ql.Config())
runner.train(timeout=5)
runner.render_window()
Animation
映像として残せるようにRGBデータを保存しながらシミュレーションします。
import srl
from srl.algorithms import ql
runner = srl.Runner("Grid", ql.Config())
runner.train(timeout=1)
runner.animation_save_gif("_Grid.gif")
# runner.animation_display() # for notebook
Replay Window
シミュレーションして、その結果を見返す機能です。
1step毎の様子を見ることができます。(GUIで表示されます)
pygameのwindowが表示できる環境である必要があります。
import srl
from srl.algorithms import ql
runner = srl.Runner("Grid", ql.Config())
runner.train(timeout=5)
runner.replay_window()
Manual play Terminal
Terminal上で手動プレイします。 環境によっては動作しない場合があります。
import srl
runner = srl.Runner("Grid")
runner.play_terminal()
Manual play Window
pygame上で手動プレイします。
'key_bind' は設定しなくても遊べますが、設定するとより環境にあった入力方法でプレイすることができます。
import ale_py
import gymnasium as gym
import pygame
import srl
# --- Atari env
# https://ale.farama.org/
gym.register_envs(ale_py)
env_config = srl.EnvConfig(
"ALE/Galaxian-v5",
kwargs=dict(full_action_space=True),
)
key_bind = {
"": 0,
"z": 1,
pygame.K_UP: 2,
pygame.K_RIGHT: 3,
pygame.K_LEFT: 4,
pygame.K_DOWN: 5,
(pygame.K_UP, pygame.K_RIGHT): 6,
(pygame.K_UP, pygame.K_LEFT): 7,
(pygame.K_DOWN, pygame.K_RIGHT): 8,
(pygame.K_DOWN, pygame.K_LEFT): 9,
(pygame.K_UP, pygame.K_z): 10,
(pygame.K_RIGHT, pygame.K_z): 11,
(pygame.K_LEFT, pygame.K_z): 12,
(pygame.K_DOWN, pygame.K_z): 13,
(pygame.K_UP, pygame.K_RIGHT, pygame.K_z): 14,
(pygame.K_UP, pygame.K_LEFT, pygame.K_z): 15,
(pygame.K_DOWN, pygame.K_RIGHT, pygame.K_z): 16,
(pygame.K_DOWN, pygame.K_LEFT, pygame.K_z): 17,
}
runner = srl.Runner(env_config)
runner.play_window(key_bind=key_bind)
引数や他のRunnerの機能に関しては Runner(Base) を見てください。